TL;DR — I split the Nemotron pipeline into four independent TensorRT engines — vit, embed, lm, post — and stitched them together with a thin Python BLS router inside Triton. The router decides per-batch whether to actually call the ViT, so text-only requests skip vision entirely instead of running it on dummy pixels. On the same RTX 6000 Ada from Part 2, text-only traffic peaks at ~85 inf/sec at concurrency 8 (p99 97 ms), while vision+text sits in the ~40–44 inf/sec range. Compared to Plan A's ~54 inf/sec multimodal peak, Plan B wins decisively on text-heavy mixes and loses on pure multimodal — exactly the trade Part 1 predicted.
This is Part 3 of three. Part 1 covers the model and the two serving strategies; Part 2 walks through Plan A — one fused TensorRT engine for the whole pipeline. Here I'll build out Plan B end to end, look at where the Python router actually fits, and benchmark the same workload across both modalities so the comparison with Part 2 lands cleanly.
Table of contents
- System
- How this fits with Part 1 and Part 2
- The intuition behind splitting the model
- What each engine does
- The router — where the "if image" lives
- Building the TensorRT engines
- Results
- When Plan B wins, and when it doesn't
System
| CUDA | 12.8 |
| GPU | NVIDIA RTX 6000 Ada Generation |
| Triton image | nvcr.io/nvidia/tritonserver:26.02-py3 |
| SDK image (perf_analyzer) | nvcr.io/nvidia/tritonserver:26.02-py3-sdk |
Same shapes as Part 2 — one image tile, fixed sequence length 1024, with the first ~256 token positions reserved for the image and the rest for text plus padding.
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
FIXED_SEQ_LEN = 1024
MODEL_NAME = "nvidia/llama-nemotron-embed-vl-1b-v2"
model = (
AutoModel.from_pretrained(
MODEL_NAME,
torch_dtype=torch.float16,
attn_implementation="sdpa",
trust_remote_code=True,
)
.to(DEVICE)
.eval()
)
model.processor.max_input_tiles = 1
model.processor.use_thumbnail = False
model.processor.p_max_length = FIXED_SEQ_LENHow this fits with Part 2
Part 1 laid out the choice between a single fused engine (Plan A) and a multi-engine BLS router (Plan B). Part 2 took Plan A all the way to a benchmark. Part 3 does the same for Plan B. The behavioral difference between the two is captured by the table below — and most of it is downstream of one decision: where the "if the request has an image" branch lives.
| Part 2 | Part 3 (this post) | |
|---|---|---|
| Idea | One ONNX → one TRT plan → one Triton model | Four ONNX exports → four TRT plans + a Python router |
| Vision on text-only | Same — ViT always runs; the scatter is a no-op | Genuinely skips ViT when pixel_values is omitted |
| Best for | Pure multimodal, simplest ops surface | Mixed traffic, modular ops, independent tuning |
The intuition behind splitting the model
It helps to think of the full Nemotron pipeline as an assembly line: image encoder, text lookup, fusion, the big language transformer, and finally a pooling step that picks one vector per row. In Part 2, the entire line is one machine — simple to install and operate, but every job (even text-only ones) passes through the camera station because the line can't branch inside a TensorRT engine.
In Part 3 we unbolt the stations. The image encoder, the token embedding lookup, the Llama backbone, and the pooling step run as four independent TensorRT engines. A small router — not a neural network, just orchestration code inside Triton — looks at each request and decides what to call. If the request has a picture, it runs embed and vit, fuses the two, then lm and post. If the request is text-only, it runs embed, lm, and post and never touches the vision engine.
That's the flexibility Part 1 promised, made real: actual skipping of vision, not a zero-tensor workaround.
The two paths look like this end to end:
Image + text:
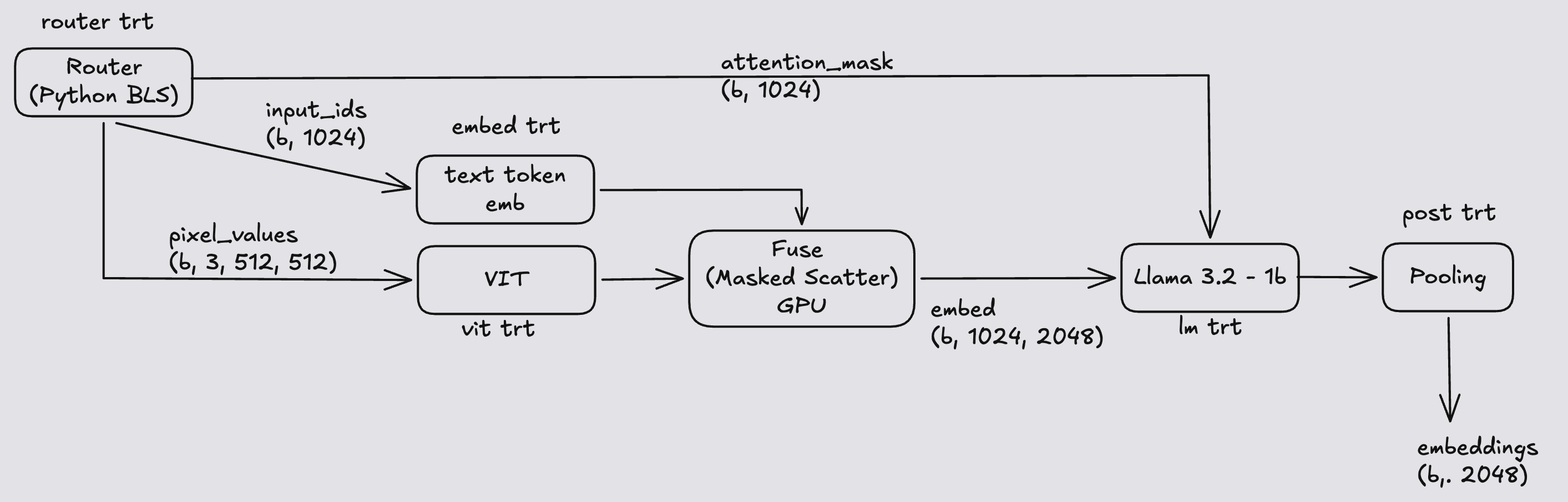
Text only:
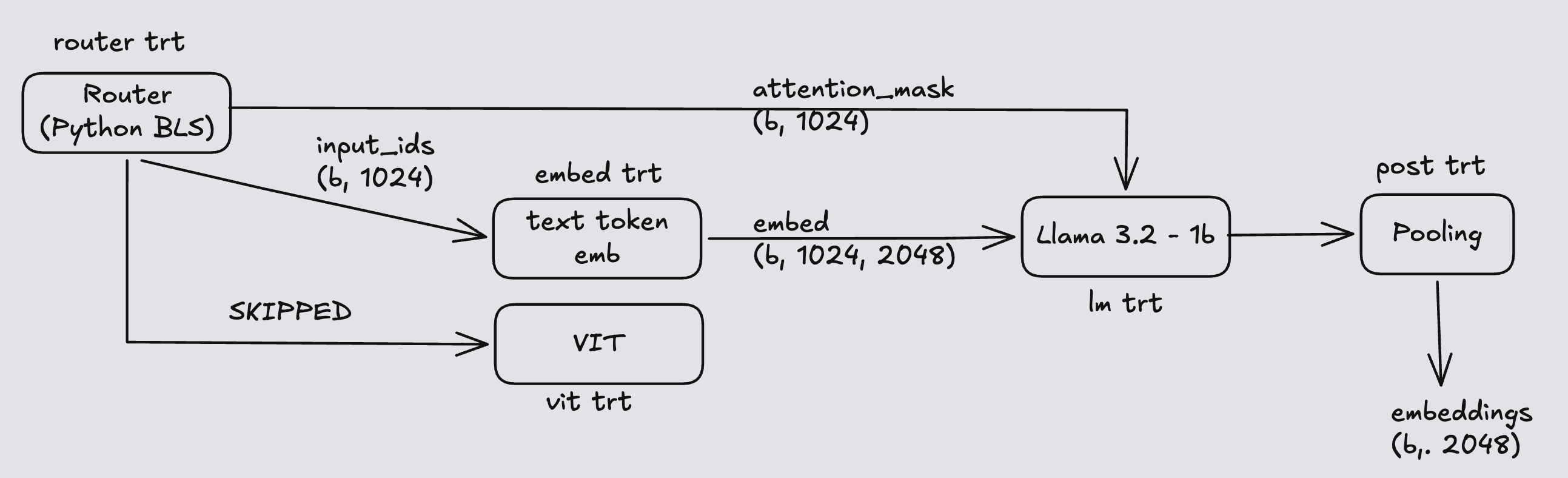
What each engine does
The math hasn't changed from Part 1: hidden size 2048, 256 vision tokens per tile, sequence length 1024 in the pinned setup. What's new is that each stage is its own ONNX export and its own .plan file, with an explicit boundary between them.
1. ViT — vision engine
Turns a 512×512 FP16 image into 256×2048 vision tokens. This is the SigLip2 path from Part 1, and it only runs when the router has real image data to send.
class NemotronVisionEncoderModule(nn.Module):
def __init__(self, model: nn.Module) -> None:
super().__init__()
self.model = model
def forward(self, pixel_values: torch.Tensor) -> torch.Tensor:
return self.model.extract_feature(pixel_values)Input: pixel_values (B, 3, 512, 512). Output: vision_embeds (B, 256, 2048).
config.pbtxt — vit (click to expand)
name: "vit"
platform: "tensorrt_plan"
max_batch_size: 32
input [
{
name: "pixel_values"
data_type: TYPE_FP16
dims: [ 3, 512, 512 ]
}
]
output [
{
name: "vision_embeds"
data_type: TYPE_FP16
dims: [ 256, 2048 ]
}
]
instance_group [
{
kind: KIND_GPU
count: 1
}
]
dynamic_batching {
preferred_batch_size: [ 4, 8, 16, 32 ]
max_queue_delay_microseconds: 1000
}2. Embed — token embedding engine
Maps token IDs to vectors using the same nn.Embedding table Llama would have used internally. For image+text requests the first 256 positions hold img_context_token_id placeholders that the router will overwrite with vision rows after the ViT runs. For text-only requests there are no image slots — just text and padding.
class NemotronEmbeddingModule(nn.Module):
def __init__(self, model: nn.Module) -> None:
super().__init__()
self.embed = model.language_model.get_input_embeddings()
def forward(self, input_ids: torch.Tensor) -> torch.Tensor:
return self.embed(input_ids)Input: input_ids (B, 1024). Output: inputs_embeds (B, 1024, 2048).
config.pbtxt — embed (click to expand)
name: "embed"
platform: "tensorrt_plan"
max_batch_size: 32
input [
{
name: "input_ids"
data_type: TYPE_INT64
dims: [ 1024 ]
}
]
output [
{
name: "inputs_embeds"
data_type: TYPE_FP16
dims: [ 1024, 2048 ]
}
]
instance_group [
{
kind: KIND_GPU
count: 1
}
]
dynamic_batching {
preferred_batch_size: [ 4, 8, 16, 32 ]
max_queue_delay_microseconds: 1000
}3. LM — language model engine
The Llama backbone. Most of the FLOPs in the pipeline live here.
class NemotronLanguageModelModule(nn.Module):
def __init__(self, model: nn.Module) -> None:
super().__init__()
self.model = model
def forward(
self,
inputs_embeds: torch.Tensor,
attention_mask: torch.Tensor,
) -> torch.Tensor:
last_hidden_state = self.model.language_model(
inputs_embeds=inputs_embeds,
attention_mask=attention_mask,
use_cache=False,
).last_hidden_state
return last_hidden_stateInputs: inputs_embeds (B, 1024, 2048) (post-fusion in the multimodal path, or raw text embeddings in the text-only path) and attention_mask. Output: last_hidden_state (B, 1024, 2048).
config.pbtxt — lm (click to expand)
name: "lm"
platform: "tensorrt_plan"
max_batch_size: 32
input [
{
name: "inputs_embeds"
data_type: TYPE_FP16
dims: [ 1024, 2048 ]
},
{
name: "attention_mask"
data_type: TYPE_INT64
dims: [ 1024 ]
}
]
output [
{
name: "last_hidden_state"
data_type: TYPE_FP16
dims: [ 1024, 2048 ]
}
]
instance_group [
{
kind: KIND_GPU
count: 1
}
]
dynamic_batching {
preferred_batch_size: [ 4, 8, 16, 32 ]
max_queue_delay_microseconds: 1000
}4. Post — pooling engine
Reduces (B, 1024, 2048) to (B, 2048) by picking the hidden state at the last non-padded token of each row. This is the same flip + argmax + gather trick from Part 2 — ONNX-friendly, no Python branches per row, bit-comparable to Plan A's pooler.
class NemotronPostprocessModule(nn.Module):
"""Last-attended-token pooling: (last_hidden, attention_mask) -> (B, H)."""
def forward(
self,
last_hidden_state: torch.Tensor,
attention_mask: torch.Tensor,
) -> torch.Tensor:
seq_len = attention_mask.shape[1]
rev = attention_mask.flip(dims=[1])
from_right = rev.argmax(dim=1).to(dtype=torch.long)
last_idx = seq_len - 1 - from_right
batch_idx = torch.arange(
last_hidden_state.shape[0],
device=last_hidden_state.device,
dtype=torch.long,
)
return last_hidden_state[batch_idx, last_idx]config.pbtxt — post (click to expand)
name: "post"
platform: "tensorrt_plan"
max_batch_size: 32
input [
{
name: "last_hidden_state"
data_type: TYPE_FP16
dims: [ 1024, 2048 ]
},
{
name: "attention_mask"
data_type: TYPE_INT64
dims: [ 1024 ]
}
]
output [
{
name: "pooled"
data_type: TYPE_FP16
dims: [ 2048 ]
}
]
instance_group [
{
kind: KIND_GPU
count: 1
}
]
dynamic_batching {
preferred_batch_size: [ 4, 8, 16, 32 ]
max_queue_delay_microseconds: 1000
}The router — where the "if image" lives
The router is the piece that makes Plan B different from Plan A. It's a Triton Python BLS (Business Logic Scripting) model — a backend that lets you write execute() in Python and call other Triton models from inside it. There is no .plan file behind it. It exists only as orchestration code.
What it does on each execute() call:
- Accepts the same client-facing inputs as a clean public API:
input_ids,attention_mask, and an optionalpixel_values. Text-only clients simply don't send the image tensor. - Coalesces many small client requests into one larger GPU batch so each downstream TRT engine sees a batch size that lands inside the
min/opt/maxenvelope it was built with. - Always calls
embed. If any request in the batch carries apixel_values, it then callsvitand runs amasked_scatterfusion in PyTorch on the GPU. Either way, it then callslmandpost. - Hands intermediate tensors between engines using
DLPackso they stay GPU-resident — no sequence-sized round-trip back to host memory between stages. - Returns
pooled (B, 2048)and splits the rows back to the originating requests.
A subtle constraint worth calling out. In this design the router is configured with instance_group.count: 1. Every additional Python backend instance is a separate process with its own CUDA context, and handing DLPack tensors between processes and TRT under load surfaced sporadic CUDA copy errors in my testing. That's not a fundamental limitation of asynchronous serving — it's a constraint of this particular Python + BLS layout. The same thing applies downstream: because the BLS path is single-threaded and sequential per execute, duplicating lm to count: 2 on the same GPU usually doesn't help. Only one engine call is in flight per execute, so a second lm instance just costs VRAM. Breaking that limit means a redesigned router that overlaps stages, and that's out of scope here.
model.py — router (click to expand)
import torch
import json
from typing import List, Optional, Tuple
import triton_python_backend_utils as pb_utils
from torch.utils.dlpack import from_dlpack, to_dlpack
EMBED_MODEL = "embed"
VIT_MODEL = "vit"
LM_MODEL = "lm"
POST_MODEL = "post"
ParsedRequest = Tuple[torch.Tensor, torch.Tensor, Optional[torch.Tensor]]
class TritonPythonModel:
"""Triton Python backend entry point — see header for the full design."""
def initialize(self, args: dict) -> None:
"""Parse static config once at model load."""
cfg = json.loads(args["model_config"])
params = {
name: spec["string_value"]
for name, spec in cfg.get("parameters", {}).items()
}
if "IMG_CONTEXT_TOKEN_ID" not in params:
raise pb_utils.TritonModelException(
"router config is missing parameter IMG_CONTEXT_TOKEN_ID; "
"set it in config.pbtxt to model.config.img_context_token_id"
)
self.img_context_token_id = int(params["IMG_CONTEXT_TOKEN_ID"])
self.device = torch.device("cuda")
def _bls_call(
self,
model_name: str,
inputs: List[pb_utils.Tensor],
requested_output_names: List[str],
) -> dict:
"""Synchronously call another model and return its outputs as a dict."""
request = pb_utils.InferenceRequest(
model_name=model_name,
inputs=inputs,
requested_output_names=requested_output_names,
)
response = request.exec()
if response.has_error():
raise pb_utils.TritonModelException(
f"BLS call to '{model_name}' failed: {response.error().message()}"
)
return {
name: pb_utils.get_output_tensor_by_name(response, name)
for name in requested_output_names
}
def _to_torch(self, tensor: pb_utils.Tensor) -> torch.Tensor:
"""Zero-copy `pb_utils.Tensor` -> `torch.Tensor` (cuda or cpu)."""
return from_dlpack(tensor.to_dlpack())
def _to_pb(self, name: str, tensor: torch.Tensor) -> pb_utils.Tensor:
"""Zero-copy `torch.Tensor` (cuda, contiguous) -> `pb_utils.Tensor`."""
if not tensor.is_contiguous():
tensor = tensor.contiguous()
return pb_utils.Tensor.from_dlpack(name, to_dlpack(tensor))
def _fuse_vision(
self,
input_embeds: torch.Tensor,
vision_embeds: torch.Tensor,
input_ids: torch.Tensor,
) -> torch.Tensor:
"""`masked_scatter` ViT features into img_context slots."""
batch_size, seq_len, hidden = input_embeds.shape
flat_embeds = input_embeds.reshape(batch_size * seq_len, hidden)
flat_vision = vision_embeds.reshape(-1, hidden)
selected = (input_ids.reshape(-1) == self.img_context_token_id)
fused = flat_embeds.masked_scatter(
selected.unsqueeze(-1).expand_as(flat_embeds),
flat_vision,
)
return fused.reshape(batch_size, seq_len, hidden)
def _parse_request(self, request: pb_utils.InferenceRequest) -> ParsedRequest:
"""Extract per-request inputs and promote them to ``self.device``"""
ids_pb = pb_utils.get_input_tensor_by_name(request, "input_ids")
mask_pb = pb_utils.get_input_tensor_by_name(request, "attention_mask")
pix_pb = pb_utils.get_input_tensor_by_name(request, "pixel_values")
if ids_pb is None or mask_pb is None:
raise pb_utils.TritonModelException(
"router request missing input_ids and/or attention_mask"
)
ids = self._to_torch(ids_pb).to(self.device, non_blocking=True)
mask = self._to_torch(mask_pb).to(self.device, non_blocking=True)
pix = (
self._to_torch(pix_pb).to(self.device, non_blocking=True)
if pix_pb is not None else None
)
return ids, mask, pix
def _run_pipeline(self, parsed: List[ParsedRequest]) -> List[torch.Tensor]:
"""Run embed → [vit + fuse] → lm → post ONCE for the whole batch."""
per_req_n = [ids.shape[0] for ids, _, _ in parsed]
ids_batch = torch.cat([t[0] for t in parsed], dim=0)
mask_batch = torch.cat([t[1] for t in parsed], dim=0)
vision_pix = [pix for _, _, pix in parsed if pix is not None]
has_vision = bool(vision_pix)
if has_vision:
pix_batch = torch.cat(vision_pix, dim=0)
# 1) embed: ONE BLS call for the whole batch.
embed_out = self._bls_call(
EMBED_MODEL,
[self._to_pb("input_ids", ids_batch)],
["inputs_embeds"],
)
embeds_pb = embed_out["inputs_embeds"]
# 2) vit + masked_scatter fusion (only when at least one request carried pixels).
if has_vision:
vit_out = self._bls_call(
VIT_MODEL,
[self._to_pb("pixel_values", pix_batch)],
["vision_embeds"],
)
embeds_t = self._to_torch(embeds_pb)
vision_t = self._to_torch(vit_out["vision_embeds"])
# ids_batch is already on cuda; no extra HtoD needed for fusion.
fused_t = self._fuse_vision(embeds_t, vision_t, ids_batch)
embeds_pb = self._to_pb("inputs_embeds", fused_t)
# 3) lm: ONE BLS call for the whole batch.
mask_pb_batched = self._to_pb("attention_mask", mask_batch)
lm_out = self._bls_call(
LM_MODEL,
[embeds_pb, mask_pb_batched],
["last_hidden_state"],
)
# 4) post: ONE BLS call for the whole batch. mask_pb_batched is reused (read-only, same device pointer); no copy.
post_out = self._bls_call(
POST_MODEL,
[lm_out["last_hidden_state"], mask_pb_batched],
["pooled"],
)
pooled_t = self._to_torch(post_out["pooled"]) # (sum_Bi, hidden)
# 5) Slice the pooled batch back into per-request rows. Row slices of
# a 2D contiguous tensor are themselves contiguous, so _to_pb's
# .contiguous() guard is a no-op here.
out: List[torch.Tensor] = []
offset = 0
for n in per_req_n:
out.append(pooled_t[offset : offset + n])
offset += n
return out
def execute(
self, requests: List[pb_utils.InferenceRequest]
) -> List[pb_utils.InferenceResponse]:
"""Run the entire batch through ONE pipeline pass."""
if not requests:
return []
# Pre-allocate the response slot for each request so we can fill them
# in order regardless of validation/pipeline outcomes.
responses: List[Optional[pb_utils.InferenceResponse]] = [None] * len(requests)
valid_idx: List[int] = []
parsed: List[ParsedRequest] = []
for i, req in enumerate(requests):
parsed.append(self._parse_request(req))
valid_idx.append(i)
if valid_idx:
try:
pooled_per_req = self._run_pipeline(parsed)
except pb_utils.TritonModelException as exc:
err = pb_utils.InferenceResponse(error=pb_utils.TritonError(str(exc)))
for i in valid_idx:
responses[i] = err
else:
for i, pooled in zip(valid_idx, pooled_per_req):
responses[i] = pb_utils.InferenceResponse(
output_tensors=[self._to_pb("pooled", pooled)],
)
# By construction every slot is filled by now — either with a real
# response, an individual validation error, or a shared engine error.
return responses # type: ignore[return-value]
def finalize(self) -> None:
returnconfig.pbtxt — router (click to expand)
# Router (Python BLS — orchestration only; no TRT plan file)
name: "router"
backend: "python"
max_batch_size: 32
input [
{
name: "input_ids"
data_type: TYPE_INT64
dims: [ 1024 ]
},
{
name: "attention_mask"
data_type: TYPE_INT64
dims: [ 1024 ]
},
{
name: "pixel_values"
data_type: TYPE_FP16
dims: [ 3, 512, 512 ]
optional: true
}
]
output [
{
name: "pooled"
data_type: TYPE_FP16
dims: [ 2048 ]
}
]
instance_group [
{
kind: KIND_GPU
count: 1
gpus: [ 0 ]
}
]
parameters [
{
# Allow GPU input tensors / DLPack — see header comment.
key: "FORCE_CPU_ONLY_INPUT_TENSORS"
value: { string_value: "no" }
},
{
key: "IMG_CONTEXT_TOKEN_ID"
value: { string_value: "128258" }
}
]
dynamic_batching {
preferred_batch_size: [ 4, 8, 16, 32 ]
max_queue_delay_microseconds: 1000
}Building the TensorRT engines
Each submodel is exported to ONNX and built with trtexec — same FP16, dynamic-shape philosophy as Part 2. The build script builds vit, embed, lm, and post in one go using a shared min/opt/max envelope so the router never has to reshape tensors between stages.
The vit build (below) is representative; the others follow the same pattern with their own input/output shapes:
docker run --rm \
--gpus "device=${GPU_INDEX}" \
--shm-size=2g \
-v "/data:/data:rw" \
nvcr.io/nvidia/tritonserver:26.02-py3 \
/usr/src/tensorrt/bin/trtexec \
--onnx=/data/onnx/vit.onnx \
--saveEngine=/data/model/vit/1/model.plan \
--fp16 \
--memPoolSize=workspace:8G \
--minShapes=pixel_values:1x3x512x512 \
--optShapes=pixel_values:4x3x512x512 \
--maxShapes=pixel_values:32x3x512x512 \
--skipInferenceOnce the engines are built, lay out the plan files and router model like this:
|_embed
|_ 1
|_ model.plan
|_ config.pbtxt
|_ vit
|_ 1
|_ model.plan
|_ config.pbtxt
|_ lm
|_ 1
|_ model.plan
|_ config.pbtxt
|_ post
|_ 1
|_ model.plan
|_ config.pbtxt
|_ router
|_ 1
|_ model.py
|_ config.pbtxtResults
Same perf_analyzer style as Part 2 — gRPC, client batch 1, 15-second time windows, GPU metrics pulled from Triton's Prometheus endpoint. The client now talks to the router model. For the multimodal sweep I use --input-data zero for all three tensors, which forces the router down the full pipeline. For the text-only sweep I feed an input.json that lists only input_ids and attention_mask, so Triton omits pixel_values and the router takes the fast path.
Vision + text — full pipeline
| concurrency | inf/sec | GPU util | p50(ms) | p90(ms) | p95(ms) | p99(ms) |
|---|---|---|---|---|---|---|
| 24 | 44.36 | 0.922 | 532 | 560 | 723 | 806 |
| 32 | 41.33 | 0.898 | 758 | 978 | 1069 | 1144 |
| 40 | 40.47 | 0.951 | 983 | 1206 | 1290 | 1461 |
| 48 | 40.88 | 0.960 | 1005 | 1742 | 1787 | 1792 |
Text only — ViT skipped
| concurrency | inf/sec | GPU util | p50(ms) | p90(ms) | p95(ms) | p99(ms) |
|---|---|---|---|---|---|---|
| 8 | 85.14 | 0.882 | 94 | 95 | 96 | 97 |
| 12 | 83.50 | 0.889 | 141 | 195 | 199 | 201 |
| 16 | 74.59 | 0.908 | 220 | 320 | 323 | 324 |
| 20 | 71.27 | 0.926 | 225 | 443 | 448 | 453 |
| 24 | 71.92 | 0.924 | 352 | 465 | 577 | 583 |
| 28 | 66.86 | 0.947 | 404 | 414 | 650 | 759 |
The text-only numbers are the headline. At concurrency 8 the router does ~85 inf/sec with a 94 ms p50 and a 97 ms p99 — basically no tail at all. That's a regime Plan A can't reach because Plan A is still running the ViT on every one of those requests, even with zeroed pixels. The vision encoder is real compute, and skipping it actually frees the GPU.
The vision+text numbers are the other side of the trade. The split path tops out around 44 inf/sec at concurrency 24, which is meaningfully lower than Plan A's ~54 inf/sec multimodal peak. That's expected: more engine boundaries, a Python hop in the hot path on every batch, a masked_scatter fusion that Plan A folds into one TRT graph, and a different instance/batching configuration. Multi-engine on a uniformly multimodal workload is paying real overhead for flexibility it isn't using.
The honest reading: Plan B isn't faster on every graph. It's the right economics for mixed traffic and the only design that genuinely skips ViT work when the input doesn't need it. If your traffic is 70% text-only, those text-only requests cost roughly half what they would in Plan A, and that frees enough GPU time to absorb the multimodal requests too.
When Plan B wins, and when it doesn't
Where Plan B is the right call. Text-heavy or mixed production traffic is the obvious one — you stop paying ViT compute on every request, and the text-only numbers above are the proof. Operationally, you can update, retune, or A/B a single engine (a new lm plan after a safety patch, say) without rebuilding a monolith. Resource planning gets easier too: in principle you can place heavy stages on different GPUs or size memory per stage, although in this single-router-instance design the practical surface area is smaller than that suggests. And when something breaks, "embed vs LM" failures show up separately in logs and metrics, which is a real debuggability win.
Where Plan A still wins. Simplicity, mostly. One config.pbtxt, one engine, one version bump. If your product is "almost every request has an image," a single fused graph avoids BLS hops and is easier to drive to peak multimodal throughput on a single GPU. There's also no Python in the inference path — the orchestration tax goes to zero.
The honest summary: if your product is mostly documents with images and you want the highest multimodal throughput per GPU with the fewest moving parts, Plan A from Part 2 is the better default. If your product is "lots of text queries with some image-bearing documents" or you need modular upgrades, Plan B pays for itself — and the text-only numbers here are the reason why.
That's the series. Part 1 covered the model, Part 2 benchmarked the single fused engine, and Part 3 took the multi-engine router as far as a working deployment goes. Pick whichever shape matches your traffic mix; just don't pick the one that pretends the choice doesn't exist.